概念
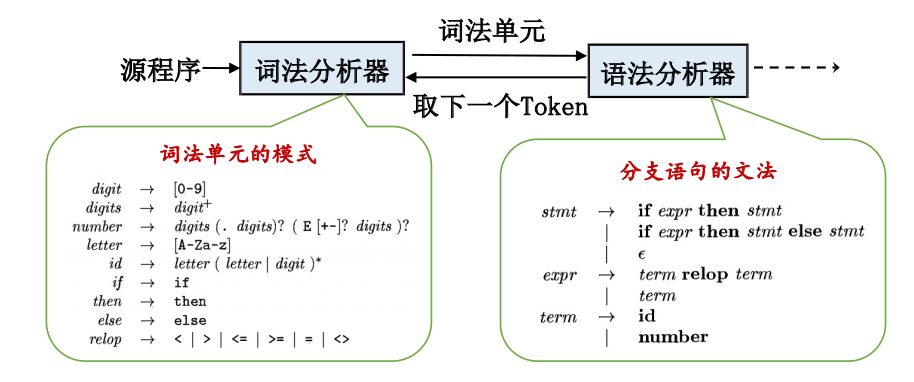
Lexical Analysis
将输⼊字符流分成多个词素,识别每个词素,根据模式⽣成相应的词法单元
|
|

Lookahead
在从左向右的分析过程中,有时候需要向前看(Lookahead)
- 空格是没有含义的
- 关键字不是保留字(reserved word)
Specification of Tokens
-
字母表
-
符号串
- 前缀(prefix),后缀(suffix),⼦串(substring),⼦序列(subsequence),逆转(reverse),长度(length)
- 连接(concatenation),指数(exponentiation),Kleene闭包(closure):L *
-
语⾔:某个给定字母表上⼀个任意的可数的符号串集合
-
正则表达式,用来描述模式
-
1 2//C语⾔标识符,字符或下划线开头,仅包含字符,下划线,数字 ( A|B|...|Z|a|b|...|z|_) (( A|B|...|Z|a|b|...|z|_) | (0|1|...|9))*
-
-
正则定义(Regular Definition):对正则表达式命名
-
1 2 3letter_ -> A | B | · · · | Z | a| b| c · · · | z | _ digit -> 0 | 1 | ... | 9 id -> letter_ ( letter_ | digit ) *
-
-
正则表达式的扩展
Recognition of Tokens
|
|
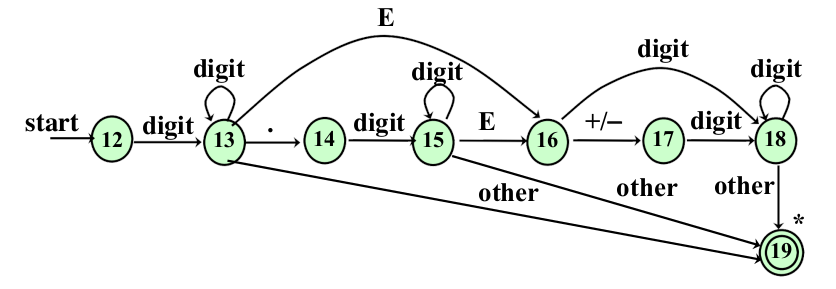
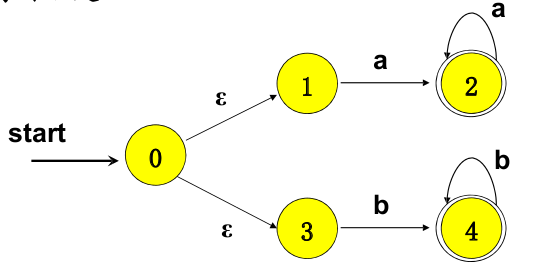
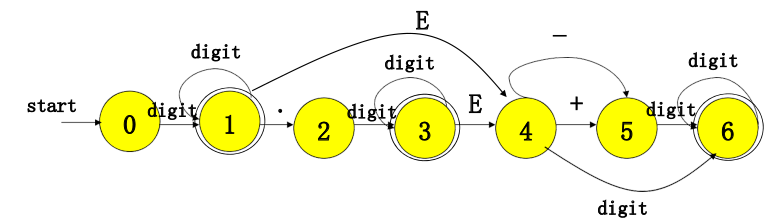
识别⽆符号数字的状态转换图
Lex
https://pandolia.net/tinyc/ch8_flex.html
根据给定的正则表达式,转换(正则->NFA -> DFA -> DFA 最小化),并自动⽣成相应的词法分析程序
|
|
FA
NFA
DFA
- 没有输⼊ ε 之上的转换动作
- 对每个状态 s 和每个输⼊符号 a,有且只有⼀条标号为 a 的边离开
NFA vs DFA
-
DFA和NFA的等价性
-
带有和不带有"ϵ - 边"的NFA的等价性
-
DFA执⾏速度更快,状态转换是确定的,不需要考虑其他选择
-
NFA表示起来更简单、转换图更小
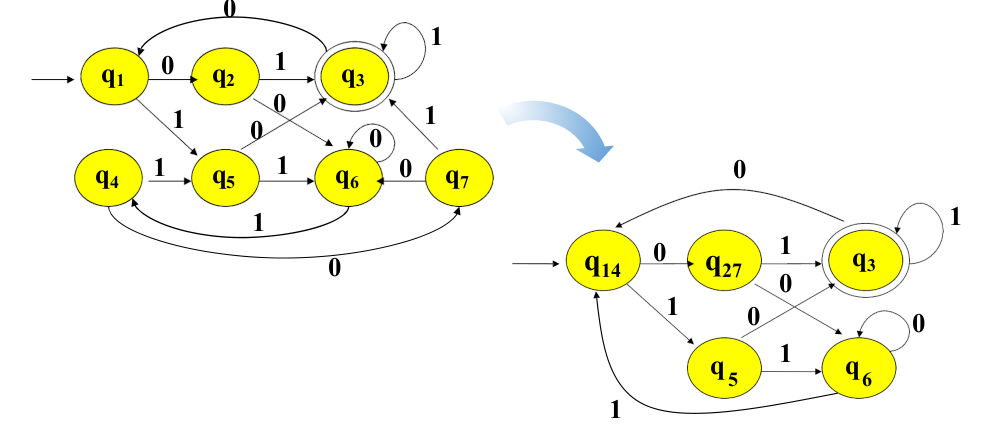
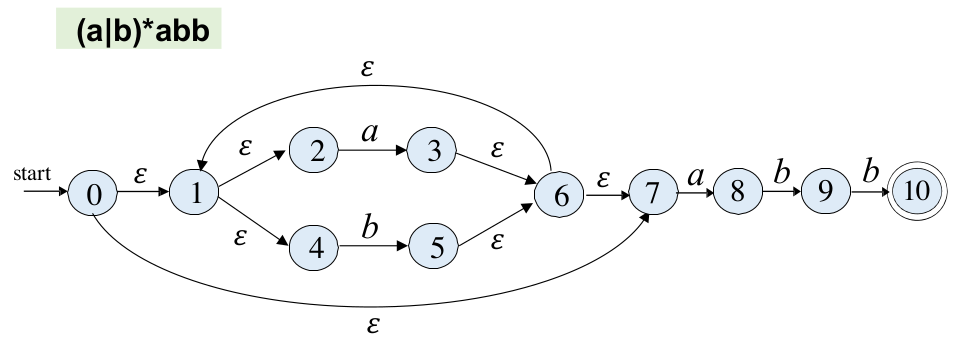
RE2NFA
小部分RE x | xy | x|y | x* 的NFA组装
NFA2DFA


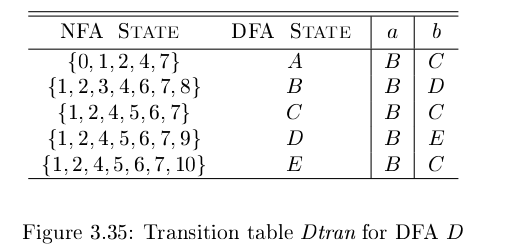
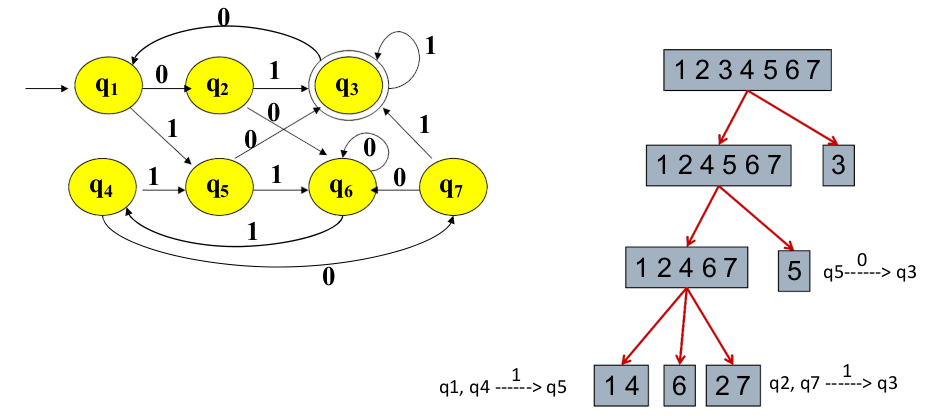
DFA最小化
如果分别从状态s和t出发,沿着标号x的路径到达的状态中只有⼀个是接受状态,则串x区分状态s和t,则两个状态s和t是可区分的
- 首先把所有状态划分为两个组:接受状态组和非接受状态组
- 任意选定⼀个输⼊符号a,判断每个组中的各个状态对于a的转换,如果落⼊不同的组中,就把该组中的状态按照转换之后的组进⾏分割,使分割后的每个组对于a的转换都会落⼊同⼀个组。
- 重复第2步,直⾄每个组中的所有状态都等价。