Features
- Volume: much larger amounts of data stored
- Velocity: much higher rates of insertions
- Variety: many types of data, beyond relational data
needs
- DB engine systems need that
- very high scalability
- support non-relation data
- sacrifice ACID properties for high scalability
Replication and Consistency
- Availability
- Consisitency
- Neteork partitions
Storage Systems
Distributed file systems
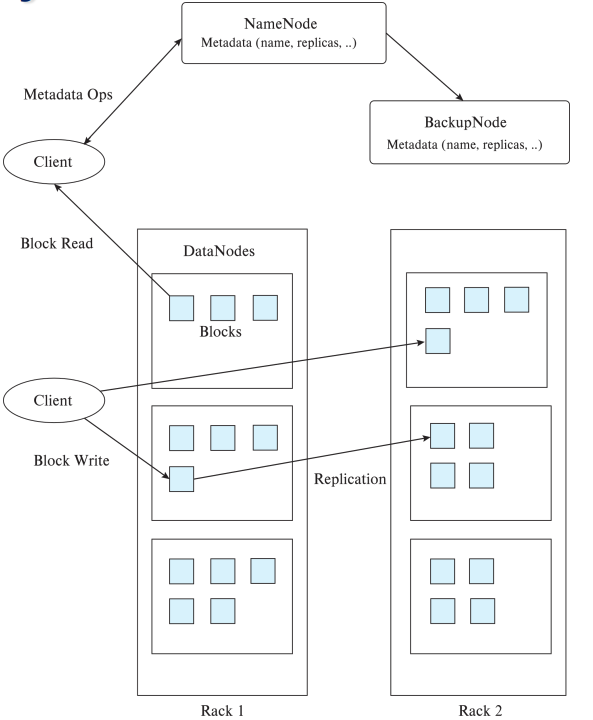
Hadoop File System Architecture
- Single Namespace for entire cluster
- Files are broken up into blocks (Typical 64MB) and replicated
- Finds location of blocks from NameNode ->Accesses data directly from DataNode
- Distributed file systems good for millions of large files
- but have very high overheads and poor performance with billions of smaller tuples
Sharding across multiple databases
- scales well, easy to implement
- Not transparent, When a database is overloaded, moving part of its load out is not easy
Key-value storage systems
Parallel and distributed databases
MapReduce Paradigm
map(k,v) -> list(k1,v1)reduce(k1, list(v1)) -> v2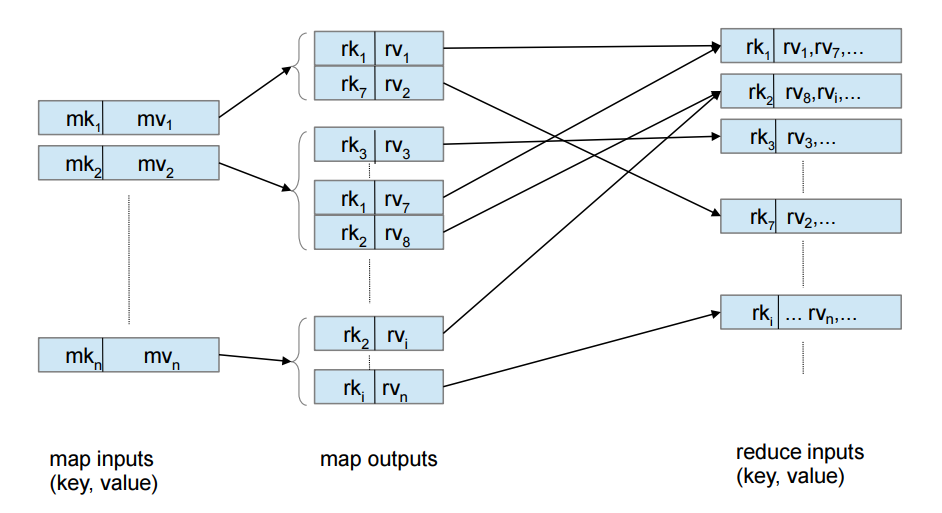
- Inspired from map and reduce operations commonly used in functional programming languages like Lisp
- Relational operations (select, project, join, aggregation, etc) can be expressed using Map Reduce
- SQL queries can be translated into Map Reduce infrastructure for exectuion
- Apache Hive SQL, Apache Pig Latin, Microsoft SCOPE
Algebraic Operations
- natively support algebraic operations such as joins, aggregation,etc natively.
- Allow users to create their own algebraic operators
- Support trees of algebraic operators that can be executed on multiple nodes in parallel
- Apache Tez, Spark
STREAMING DATA
Querying
-
Windowing
-
Continuous queries
-
Algebraic operators on streams
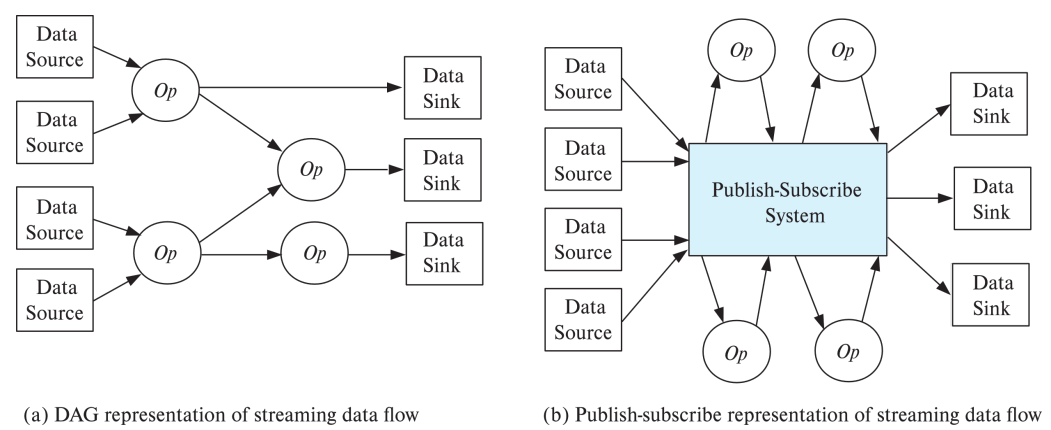
-
Pattern matching
- Complex Event Processing (CEP) systems
- Microsoft StreamInsight, Flink CEP, Oracle Event Processing
Lambda architecture
- Easy to implement and widely used
- But often leads to duplication of querying effort, once on streaming system and once in database