概括
- 如何判断一个数据在cache中
- 数据查找Data Identification
- 如需访问的数据在cache中,存放在什么地方
- 地址映射Address Mapping
- Cache满了以后如何处理
- 替换策略Placement Policy
- 如何保证cache与memory的一致性
- 写入策略Write Policy

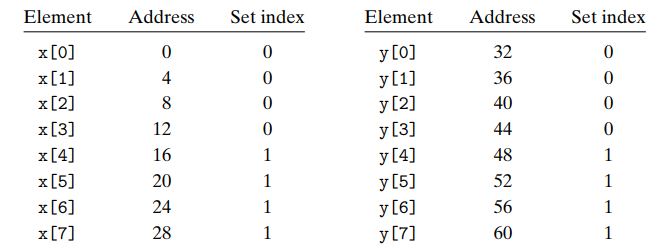
address map
高速缓存(cache)与主存的地址映射是由硬件自动完成的
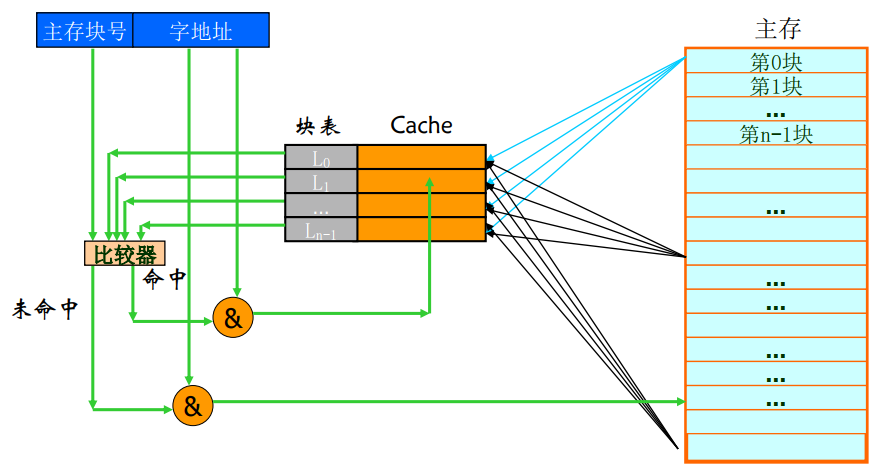
- 直接(direct mapped)
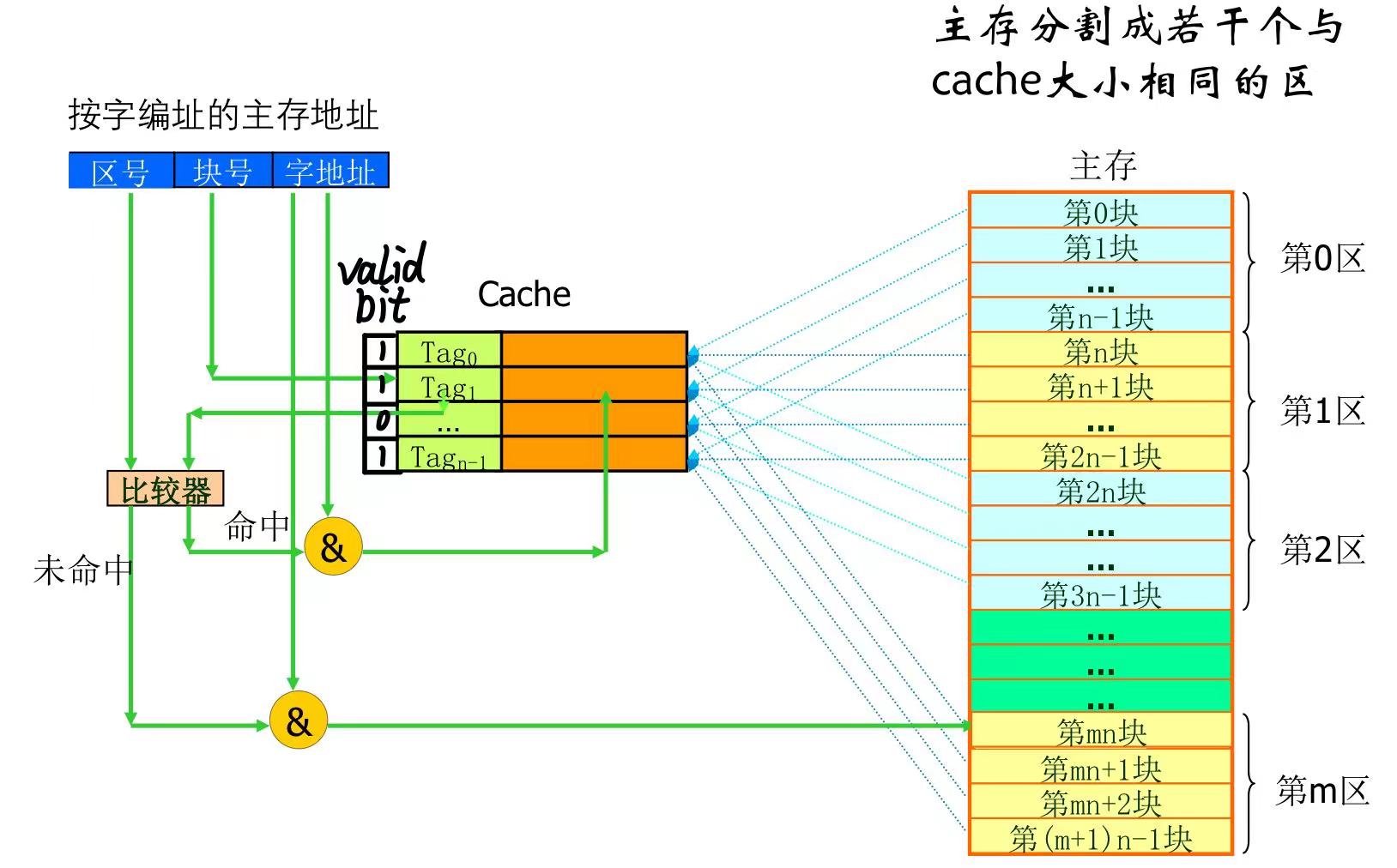
- 查找速度快,命中率相对前者稍低,适合大容量Cache
- ping-pong效应
- 全相联(fully-associated),即对页面可以放置的内存位置没有限制
- 相联(set-associated)
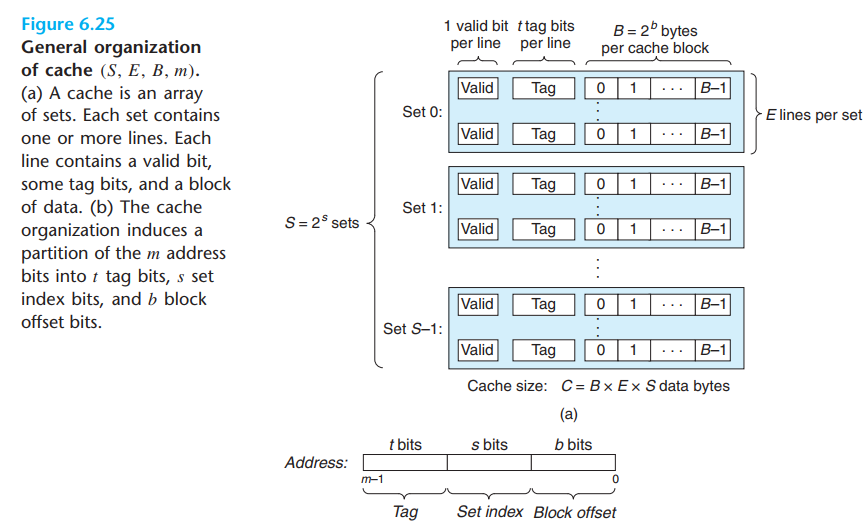
- Direct-Mapped Caches ,A cache with exactly one line per set (E = 1)
- Fully-Associated CAches,S = 1 set
- set index in middle
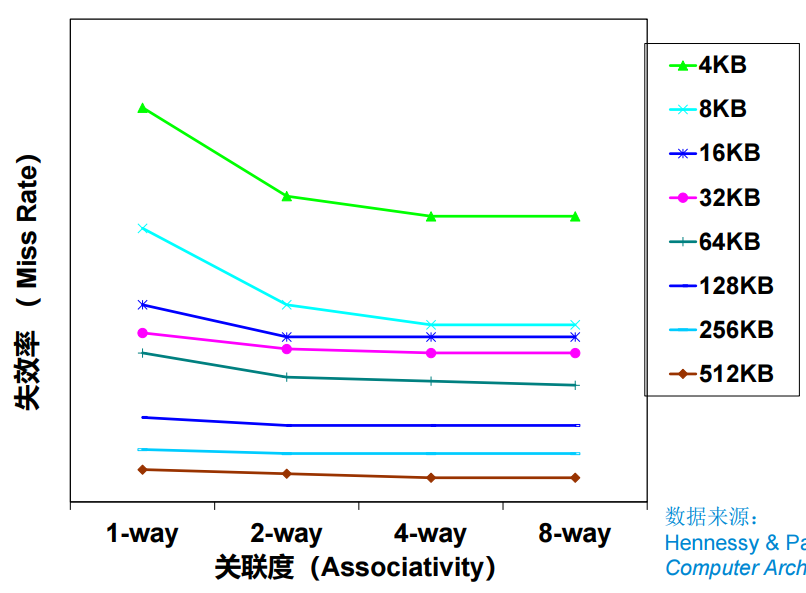
cache miss
- cold(compulsory) miss
- conflict miss
- 由集合关联性(set-associativity)引起
- capacity misses
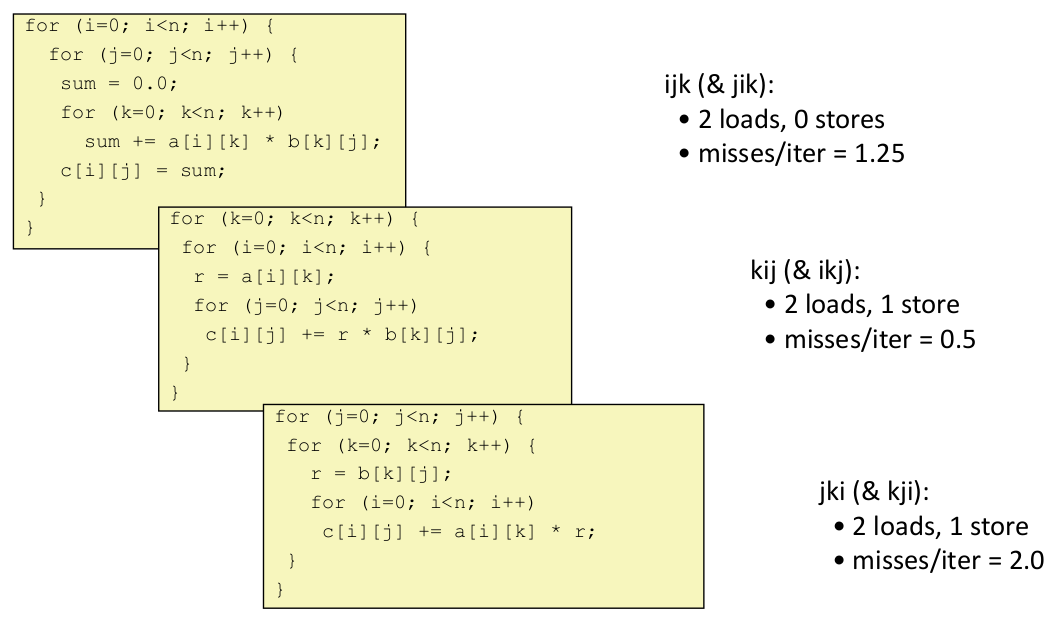
GEMM
|
|

- 分块确保每次取的cache被充分使用,不发生颠簸
- 每次(分块)迭代的失效数:2n/B * B^2/8 = nB/4
- 总共的错失数:nB/4 * (n/B)^2 = n^3 /(4B)
- 可能大的分块大小 B, 但限制 3B^2 < C
Write Policy
- Cache hit
- write through:写入cache,同时写入mem
- write back:只写回cache,当发生替代时再写回mem
- Cache miss
- write allocate:将block调入cache再写
- no write allocate:直接写mem
Placement Policy
- LRU
- 每次访问更新关联set内每一line的排序
- 近似LRU
- 添加脏位
- LFU
- Random
- 对特殊情况的处理比较良好
☆一致性
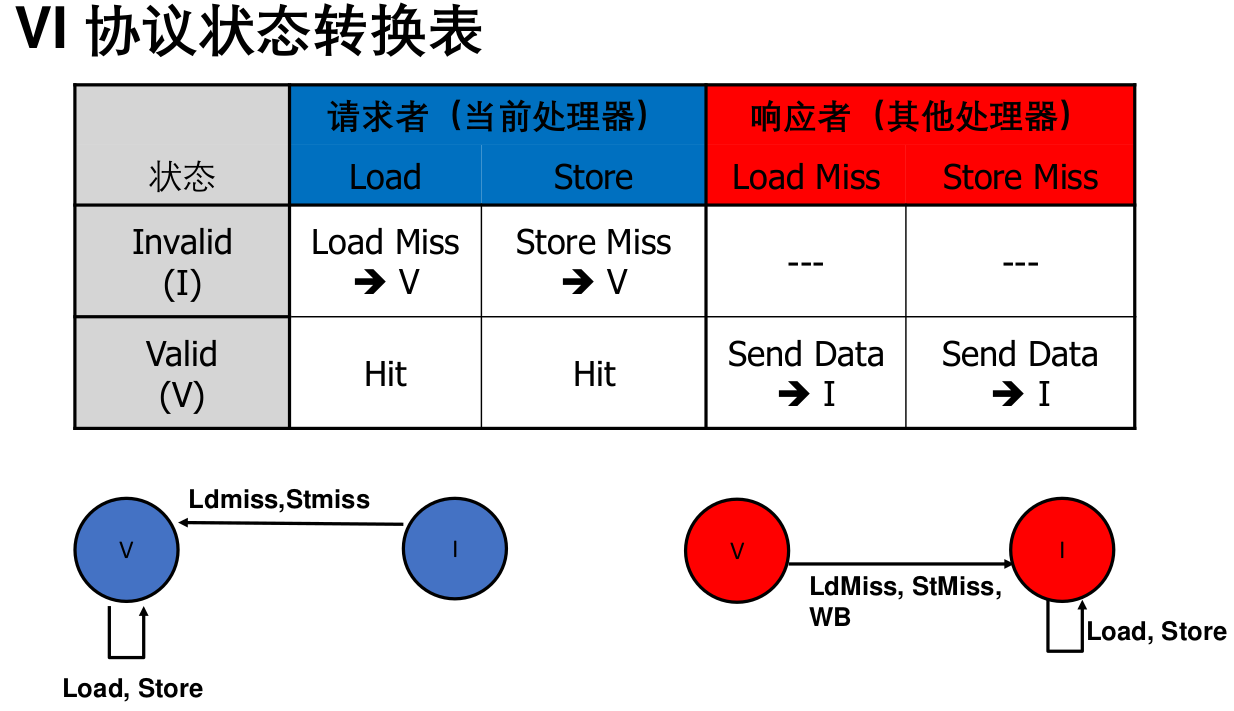
VI
- 在多个私有高速缓存中,最多只能有一个拥有数据块的最新拷贝,即使是只用于读的拷贝,这会影响共享的只读数据结构(如指令)的访问性能
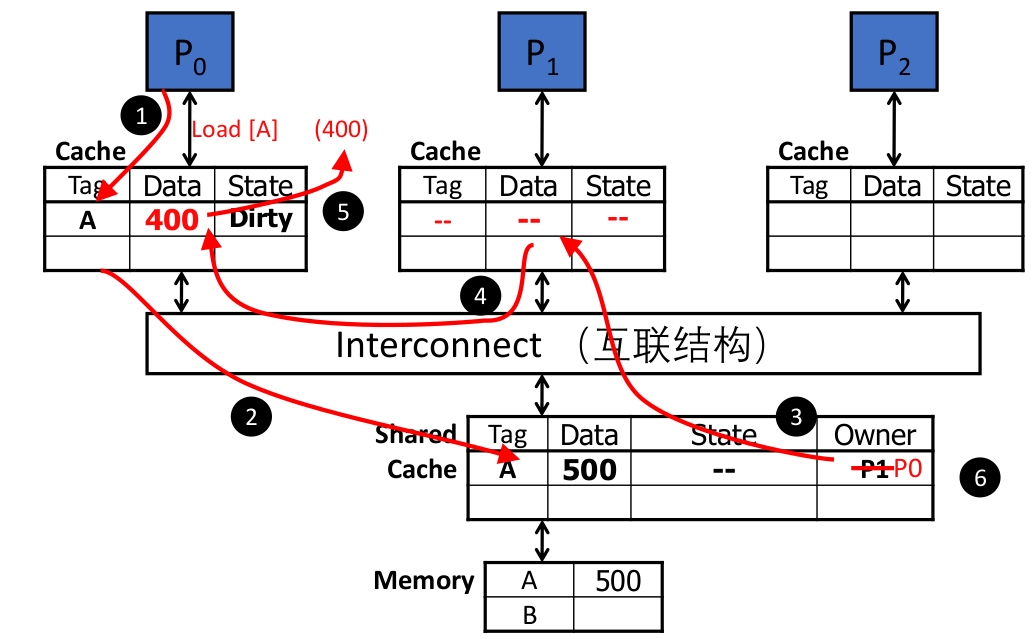
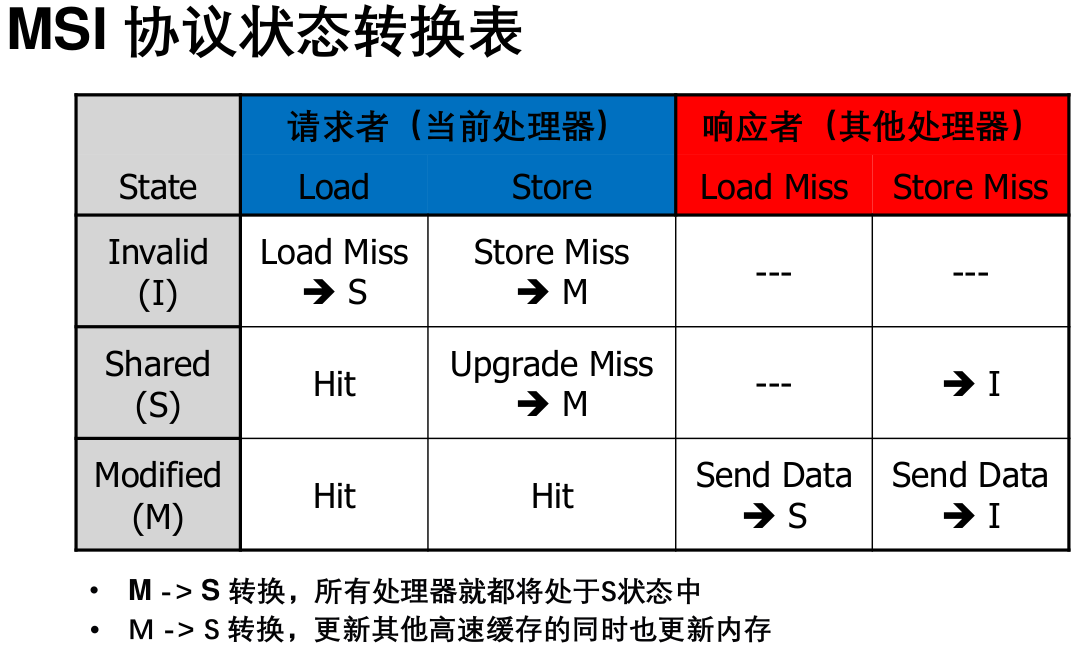
MSI
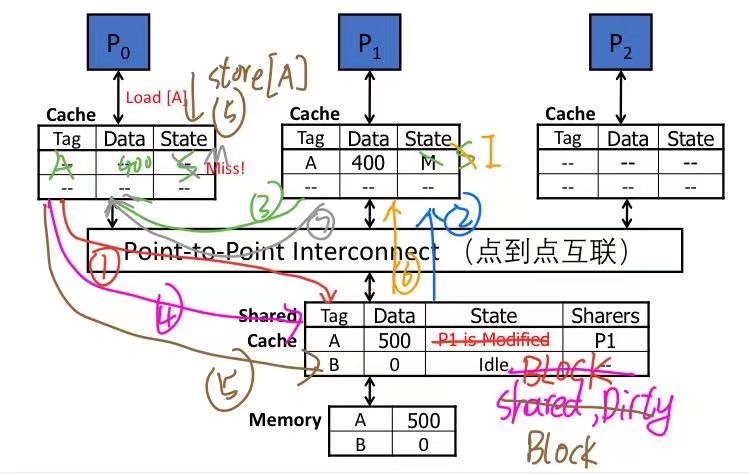
假共享问题
P1和P2的动作是串行的,出现乒乓现象,还增加了数据块在不同处理器之间来回传送的开销
|
|
other
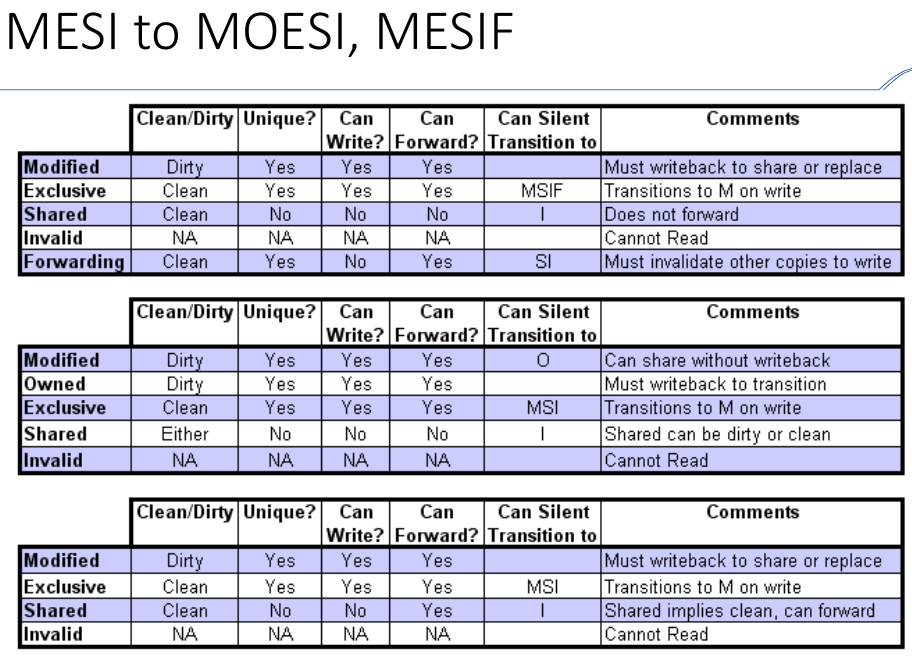
题
1.存储容量为16K*4的DRAM芯片,其地址引脚和数据引脚各是
2.假定采用多模块交叉存储器组织方式,存储器芯片和总线支持突发传送(burst),CPU通过存储器总线读取数据的过程为:发送首地址和读命令需1个时钟周期,存储器准备第一个数据需8个时钟周期(即CAS潜伏期=8),随后每个时钟周期总线上传送1个数据,可连续传送8个数据(即突发长度=8)。若主存和cache之间交换的主存块大小为64B,存储宽度和总线宽度都为8B,则cache的一次缺失损失(缺失开销)至少为(17)个时钟周期。
3.假定CPU通过存储器总线读取数据的过程为:发送地址和读命令需1个时钟周期,存储器准备一个数据需8个时钟周期,总线上每传送1个数据需1个时钟周期,若主存和cache之间交换的主存块大小为64B,存取宽度和总线宽度都为8B,则cache的一次缺失损失(缺失开销)至少为( 80)个时钟周期。
4.缓存到地址映射中__全相联映射___比较多的采用“按内容寻址”的相联存储器来实现