电路基础
-
组合逻辑电路(combinational Logic )
- 输出仅为输入的函数,与历史无关
-
时序逻辑电路(sequential Logic)
- 存储器、寄存器
-
Max delay = Setup Time + CLK-to-Q delay + CL delay

RISC-V单周期
单周期:指令周期==时钟周期

- 数据通路/控制信号
- MUX多路选择器(Multiplexer)
- ImmSel的值由指令类型决定(I,S,……),高位(imm[31:12])填充符号位
- ALUSel : Add/Sub/…
- BrLT = 1 ,if A < B
- BrEq = 1 ,if A = B
- BrUn =1 , select unsigned comparision
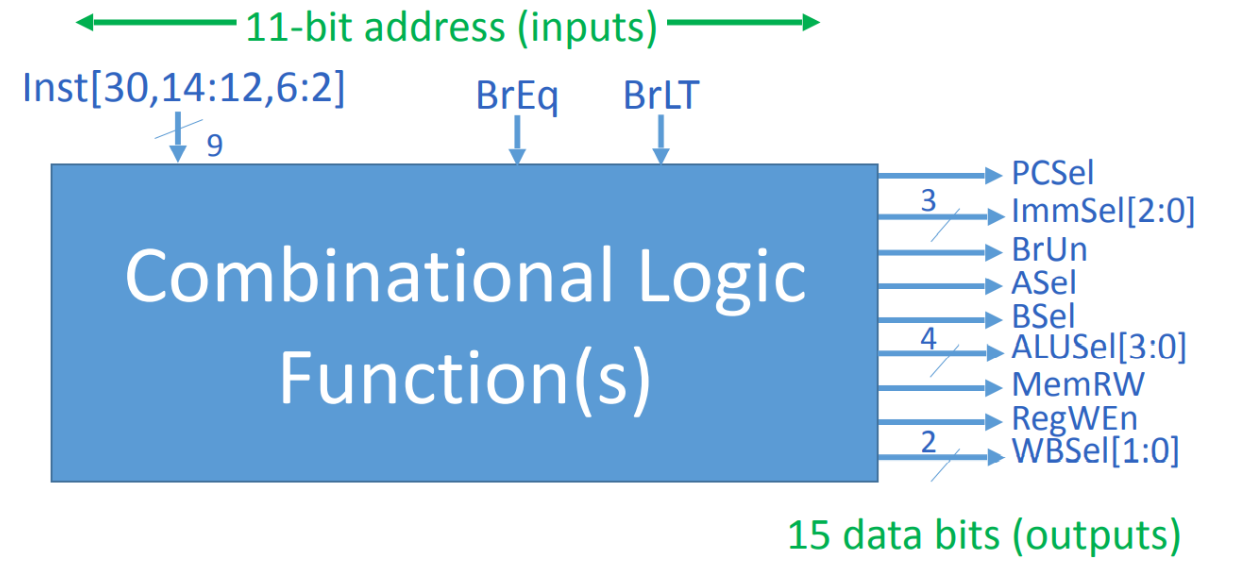
控制单元
组合逻辑控制器
FPGA

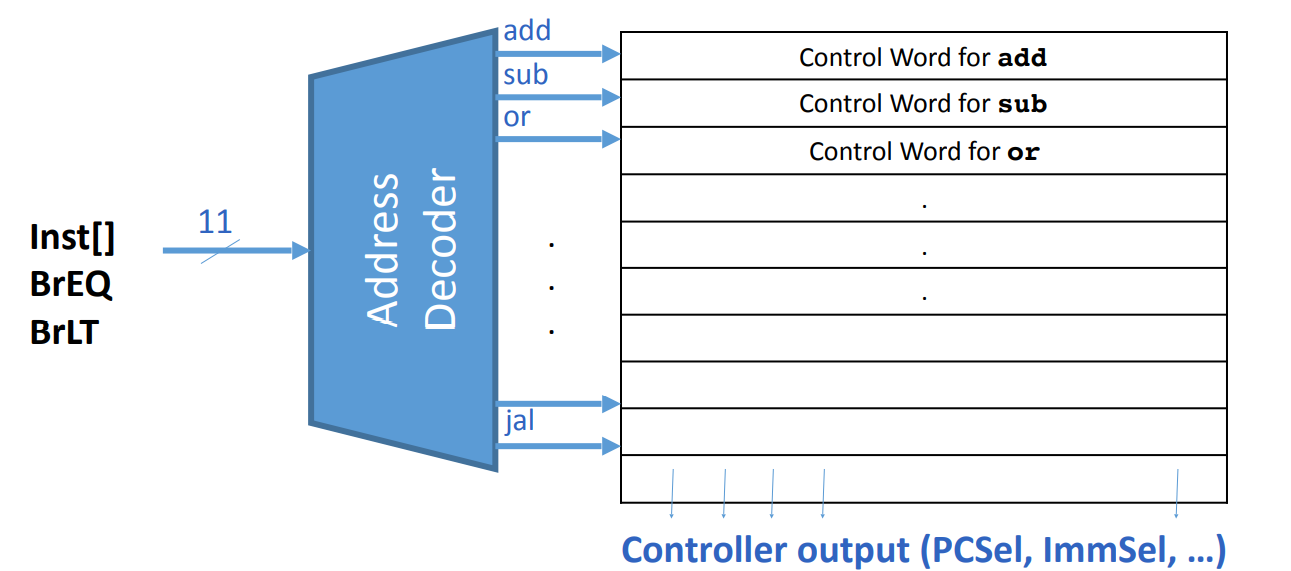
ROM控制器
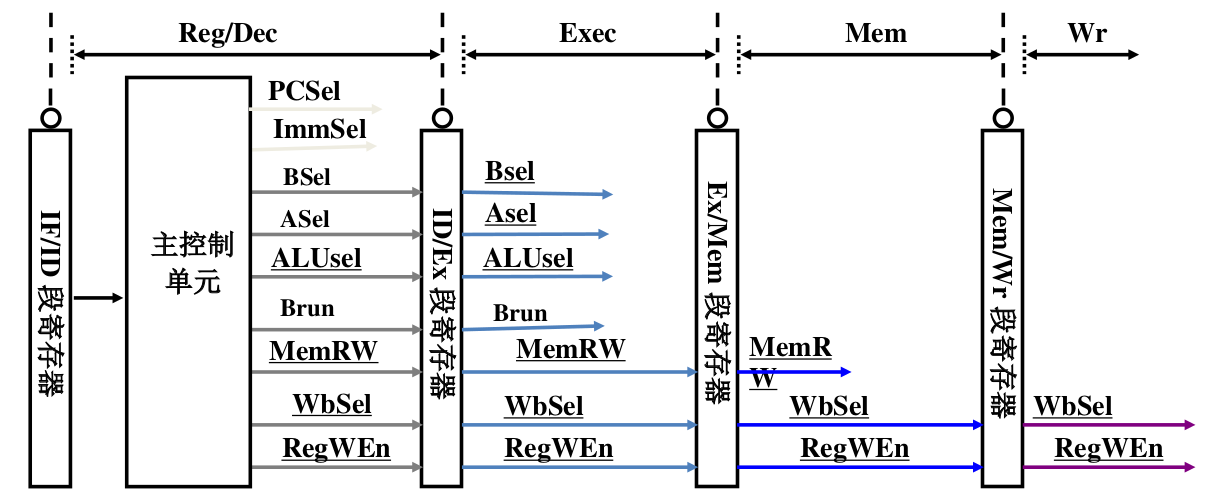
RISC-V pipeline
- 段寄存器除了存储上一段的结果,还存储本段以及后面段所用的控制信号,段寄存器宽度不同
- 流水线方式下,流水段寄存器增加了延迟,一条指令的执行时间反而加长了。但由于流水线执行提升了指令吞吐率,程序总的执行时间缩短了
- 流水线处理器效率高
- 流水段会将中间结果和控制信号逐级传递
- 流水线会发生各类冒险
hazards
-
structural hazards:所需的硬件部件正在为之前的指令工作(同时读写M与R)
- 指令存储器和数据存储器相互独立
- 寄存器文件设置相互独立的读口和写口(半周期读,半周期写)
- 寄存器堆先写后读,D阶段的指令可以在同一个周期内得到W阶段写回的数据
-
data hazards:数据依赖性需要等待之前的指令完成数据的读写
- 软件解决方案:插入空指令
- 硬件解决方案:流水线停顿:停止后发射的指令,继续执行前发射的指令
- 前向传递( forwarding )/旁路网络(bypass network),不等到WB,就将产生的结果直接传送到当前周期需要结果的功能单元的输入端:E结果传到E头 ,M结果传到M/E头
-
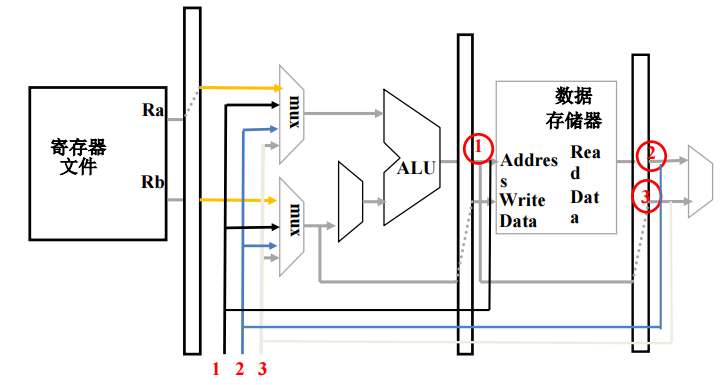
- 前向通路不能解决“读存储器-使用 ”冒险(lw $1 4($2) , addi $3 $1 0x10),相邻指令还需要一NOP
- 消除相关性:编译调度
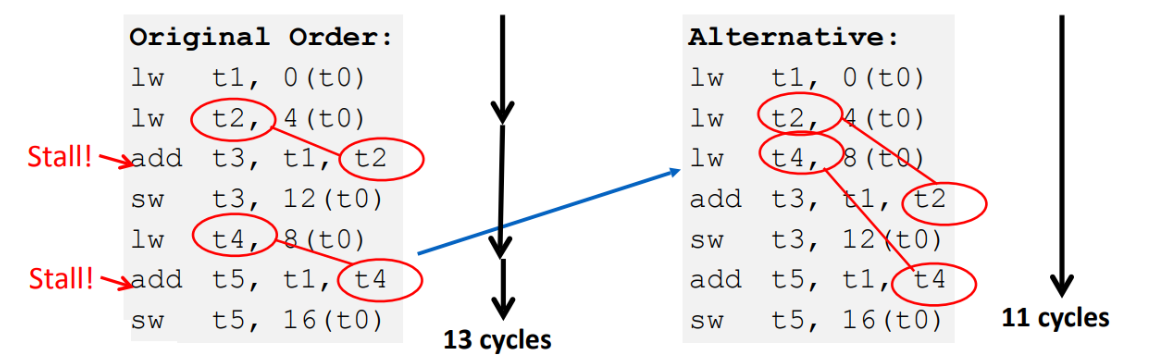
-
control hazards:转移指令引起:需要根据指令的结果决定下一步
-
控制冒险无法完全消除,会严重影响CPI
- 少用if
-
最简单的方法:清空
-
优化:转移方向和转移地址计算提前到D段
-
优化后 BEQ 的CPI=2
支持pipeline的数据通路
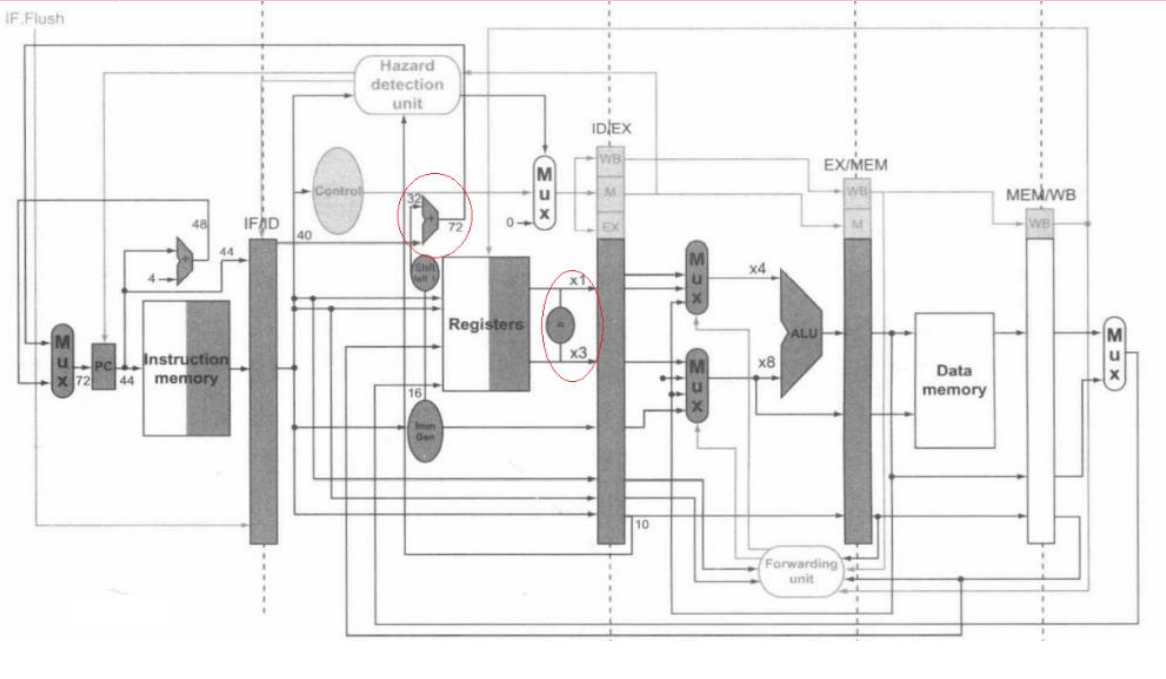
-
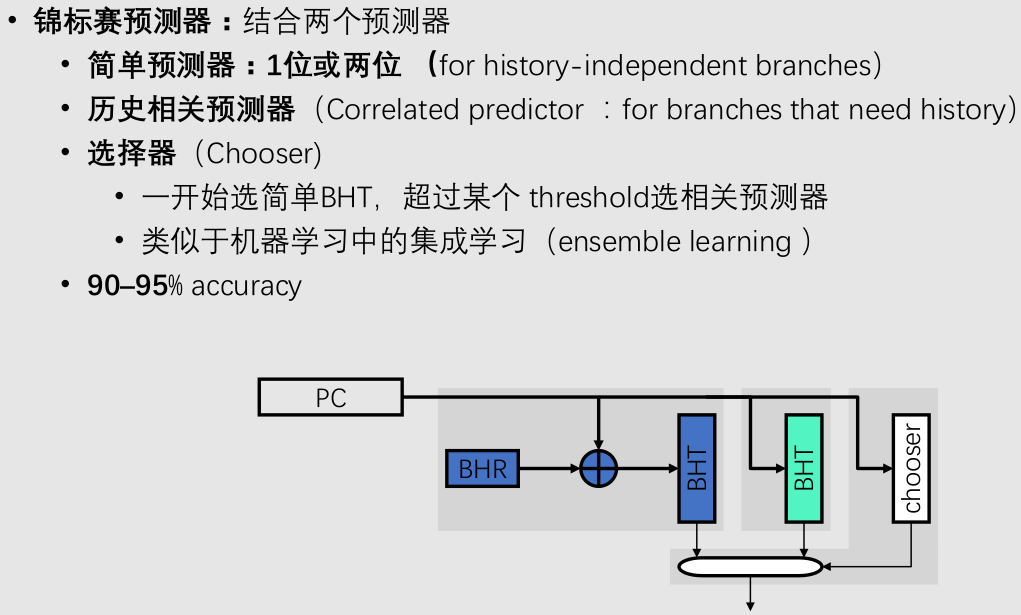
动态转移预测
一位预测

两位预测

局部历史预测
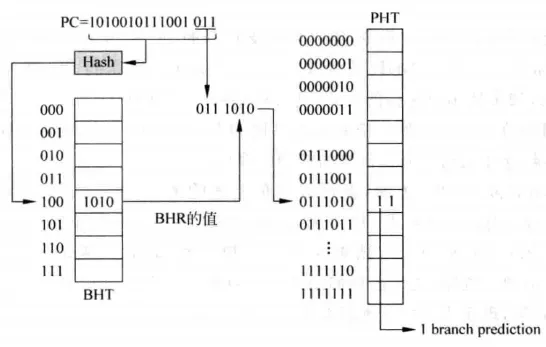
全局历史预测
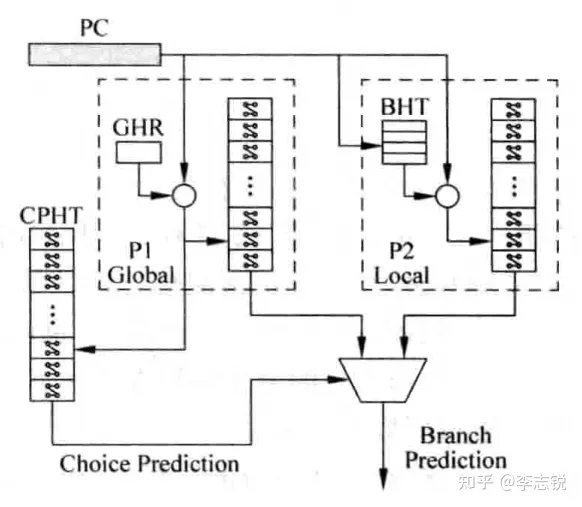
混合预测器
https://zhuanlan.zhihu.com/p/450544699
https://zhuanlan.zhihu.com/p/148736041
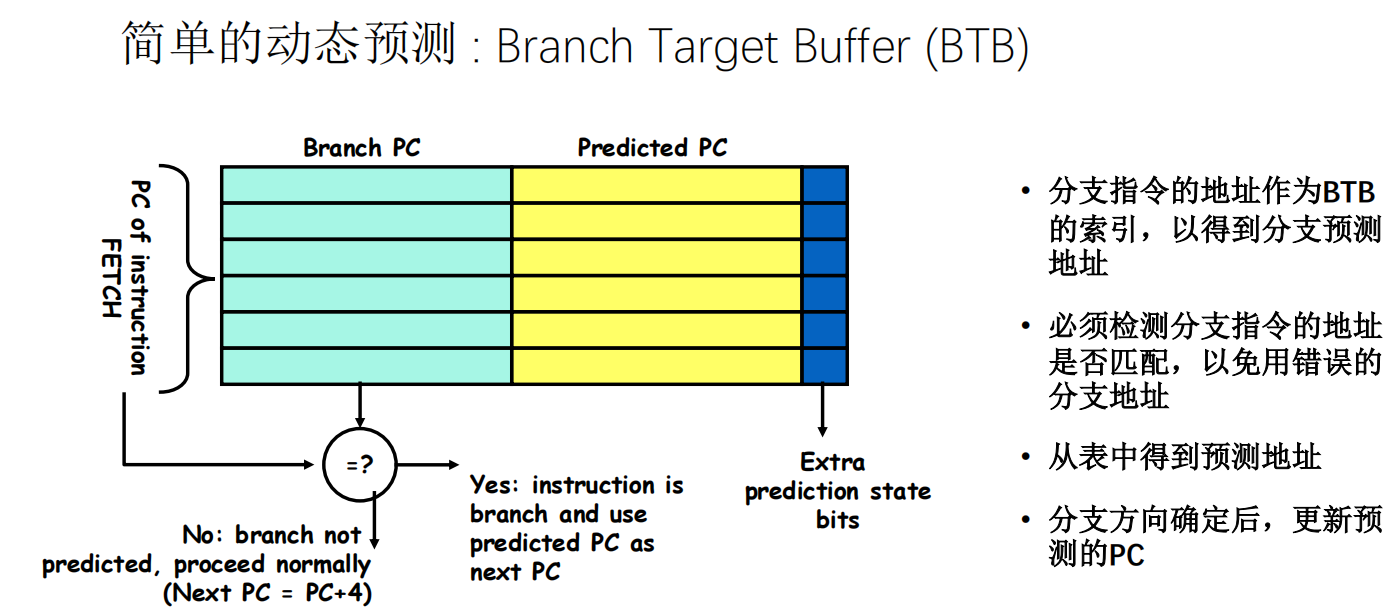
BTB
MultiIssue
-
利用指令级并行性(Instruction Level Parallism: ILP )获得CPI < 1
-
超标量结构处理器每个时钟周期并行发射和执行多条指令
深流水问题
- 开销增加
- 复杂度:流水段越多,前向通路复杂
- 性能下降
- 流水段寄存器个数增加,一条指令的延迟就越大
- 重叠执行的指令越多 → 可能出现的相关性越多 → 停顿的可能性就越大
- 时钟频率高,功耗越大
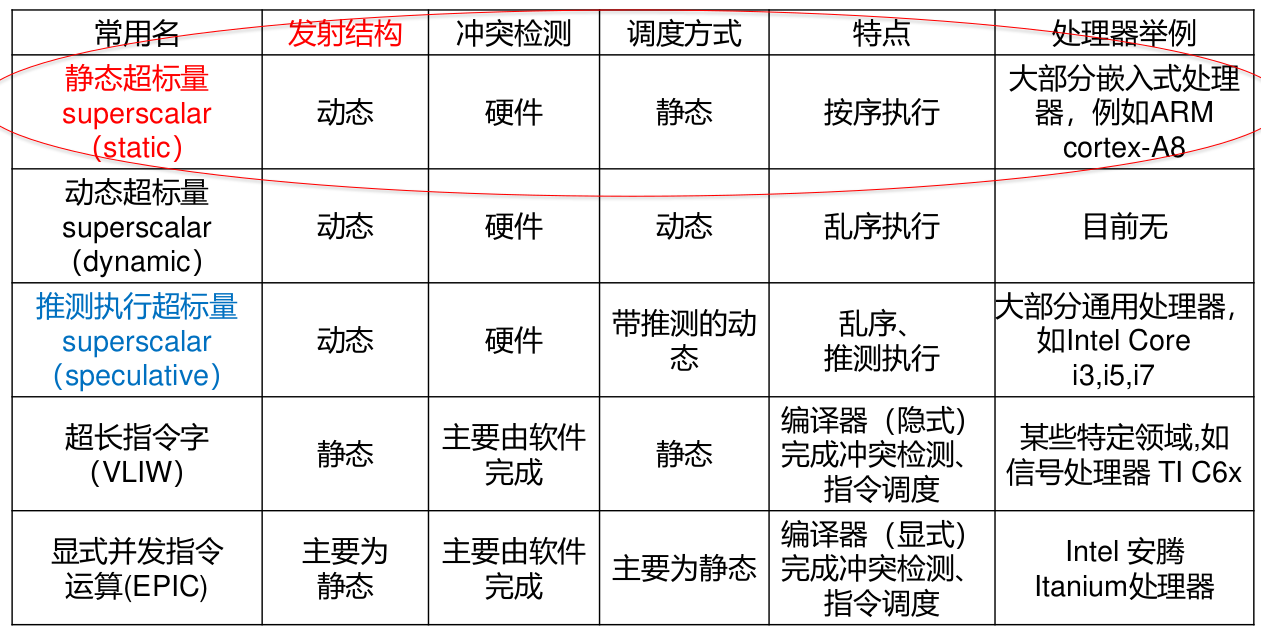
静态超标量
-
静态调度,编译器尽力做:
-
避免相邻指令使用同一部件(结构冒险)
-
避免相邻的指令有数据依赖关系(数据相关)
-
|
|
- 动态发射结构:
- 每个周期由控制逻辑判断是发射一条还是多条指令, 还是不发射指令;
- 结构冒险:编译器实在无法避免时,能检测出冒险,一次只发送一条;
- 数据冒险:编译器实在无法避免时,能检测出冒险,如果检测到冒险,要么把两条都停顿、要么停顿两条中的一条;
- 控制冒险: 当转移预测错误时、清空流水线,从正确位置重新开始执行。
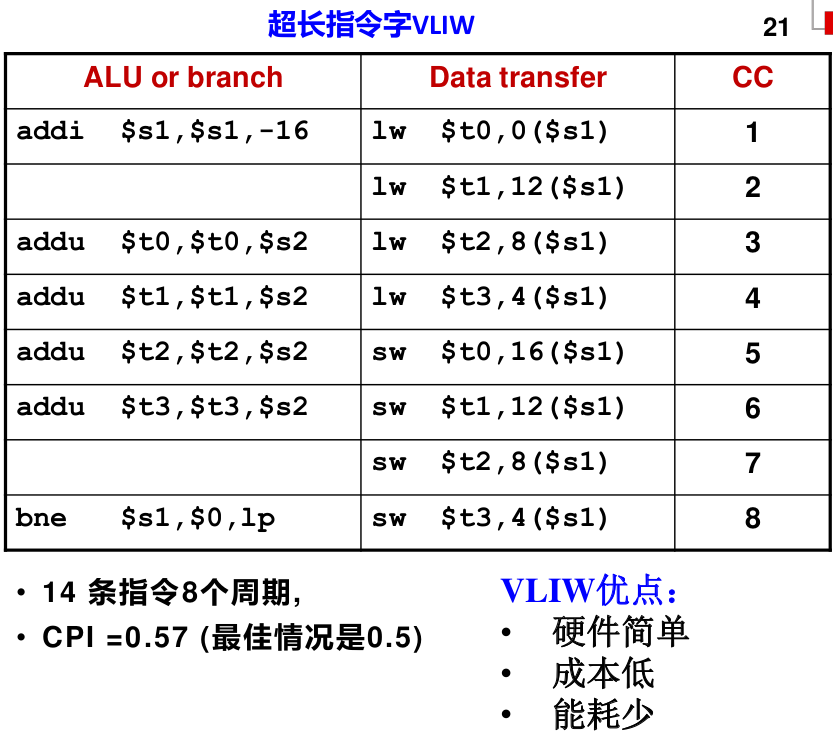
VLIW
- 将多个相互无依赖的指令封装到一条超长的指令字中
- CPU中有对应数量的ALU完成相应的指令操作
- 指令之间的依赖性检测和调度由编译器来完成
- 多用于DSP(domain specific processor)
- 编译复杂、编译时间长
- 代码膨胀
- 锁步(lock step) 机制
- 目标代码不兼容
乱序超标量

-
数据相关性
- (Read After Write)RAW相关
-
消除“假”数据相关性
-
(Write after Write)WAW 相关
-
(Write after Read) WAR 相关
-
寄存器重命名,以实现乱序
-
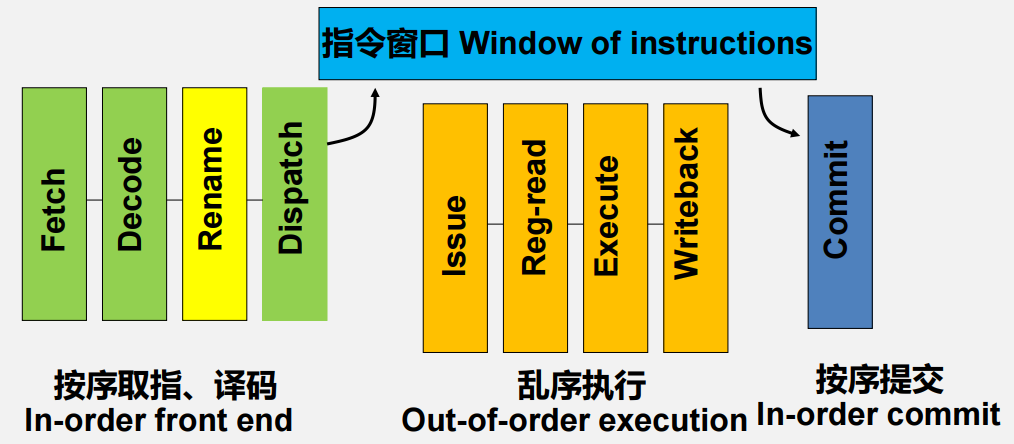
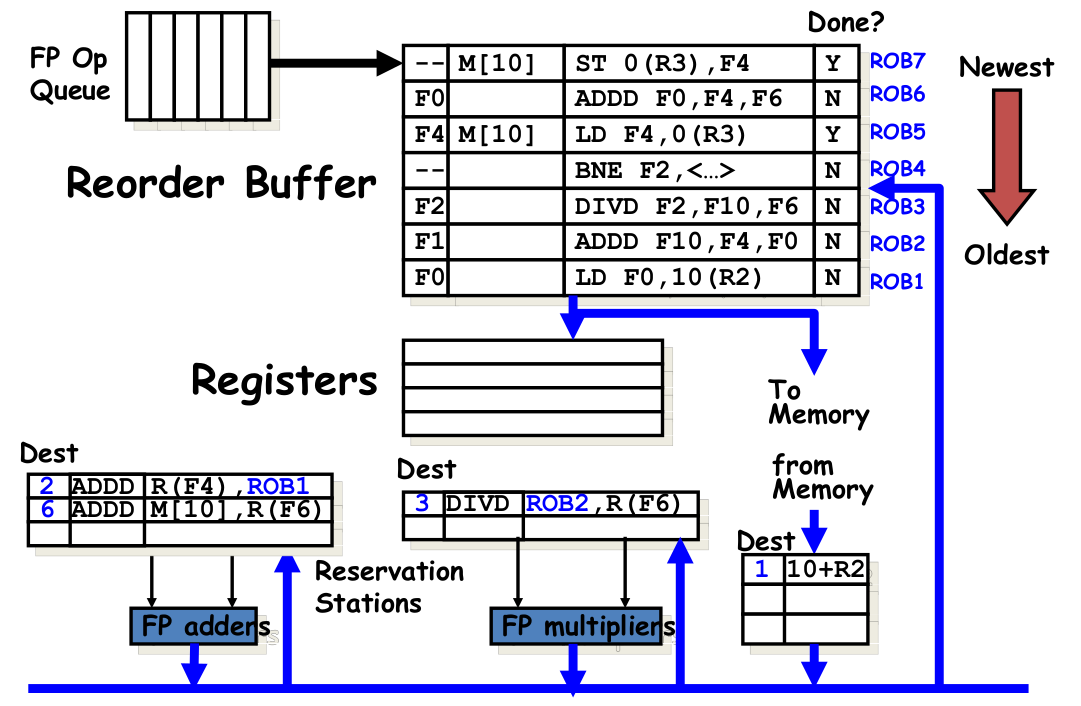
Tomasulo Algorithm
https://zhuanlan.zhihu.com/p/496078836
- Register renaming
- Multiple iterations use different physical destinations for registers (dynamic loop unrolling).
- Dynamic hardware schemes can unroll loops dynamically in hardware
概括
- 猜测执行(猜测转移方向、访存地址相关性…)
- 相关性检查 (检查出真相关)
- 寄存器换名(更多的物理寄存器)
- 指令缓冲区(庞大的指令窗口)
- 多个执行部件:乱序执行
- 提交单元:按序提交
题
https://www.cnblogs.com/yangzhaonan/p/10415644.html
https://blog.csdn.net/xuchaoxin1375/article/details/118186611
1.时钟周期,机器周期,指令周期
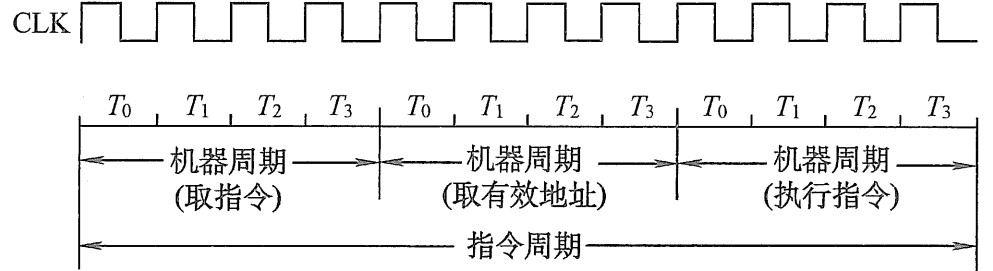
2.有关指令周期的叙述,错误的是:
A.指令周期的第一个阶段是取指令阶段
B.乘法指令和加法指令的指令周期一样长
C.一个指令周期由若干个机器周期或时钟周期组成
D.单周期处理器的指令周期就是一个时钟周期
3.下面有关MIPS、RISC-V架构的lw/sw指令数据通路设计的叙述,哪些是正确的?
- 在lw/sw指令数据通路中,一定有一个立即数扩展部件用于偏移量的扩展
- 在lw/sw指令数据通路中,ALU的控制信号一定为“add”(即ALU做加法)
- 寄存器堆的“写使能(RegWrite)”信号在lw指令执行时为“1”,在sw指令执行时为“0”
- 数据存储器的“写使能(MemWrite”信号在lw指令执行时为“0”,在sw指令执行时为“1”
|
|
4.以下是关于结构冒险的叙述:
\1. 结构冒险是指同时有多条指令使用同一个资源
\2. 避免结构冒险的基本做法是使每个指令在相同流水段中使用相同的部件
\3. 重复设置功能部件可以避免结构冒险
\4. 数据cache和代码cache分离可解决两条指令同时分别访问数据和指令的冒险
|
|
5.考虑以下代码,将一组向量中的每一个浮点数与一个常量相乘。
I1: loop: LD.D F0, 0(R1) // 从内存将一个元素读入浮点寄存器 F0
I2: MUL.D F0, F2, F0 // 乘以常量
I3: ST.D F0, 0(R1) // 将运算结果存入内存
I4: DDI R1, R1, 8 // 修改数组下标
I5: BNE R1, R2, loop // 数组未结束则跳转
哪些指令之间存在反相关(WAR)?
A.I2 和 I3 关于F0
B.I3和I4 关于 R1
C.I1 和 I2 关于 F0
D.I4 和 I5 关于R1
|
|
6.下面列出了开发指令级并行性所使用的技术,哪些技术是只基于“硬件”的?
A.Register renaming (寄存器换名)
B.Reorder buffer (重排序缓冲器)
C.Superscalar (超标量)
D.Dynamic scheduling (动态调度)
E.VLIW
|
|