- 下图是一个实现了RV32I指令集的单周期处理器的数据通路,为使得不同的指令在同一个处理器中完成不同的功能,控制器对指令译码后,要发出不同的控制信号。表格中罗列了部分指令的控制信号。其中 表示控制信号可以任意取值;BrUn为1时,表示比较指令的两个比较值是无符号数;Immsel取不同的值,是因为不同的指令中的立即数在指令中不同的位置、以及立即数扩展的方法不同。
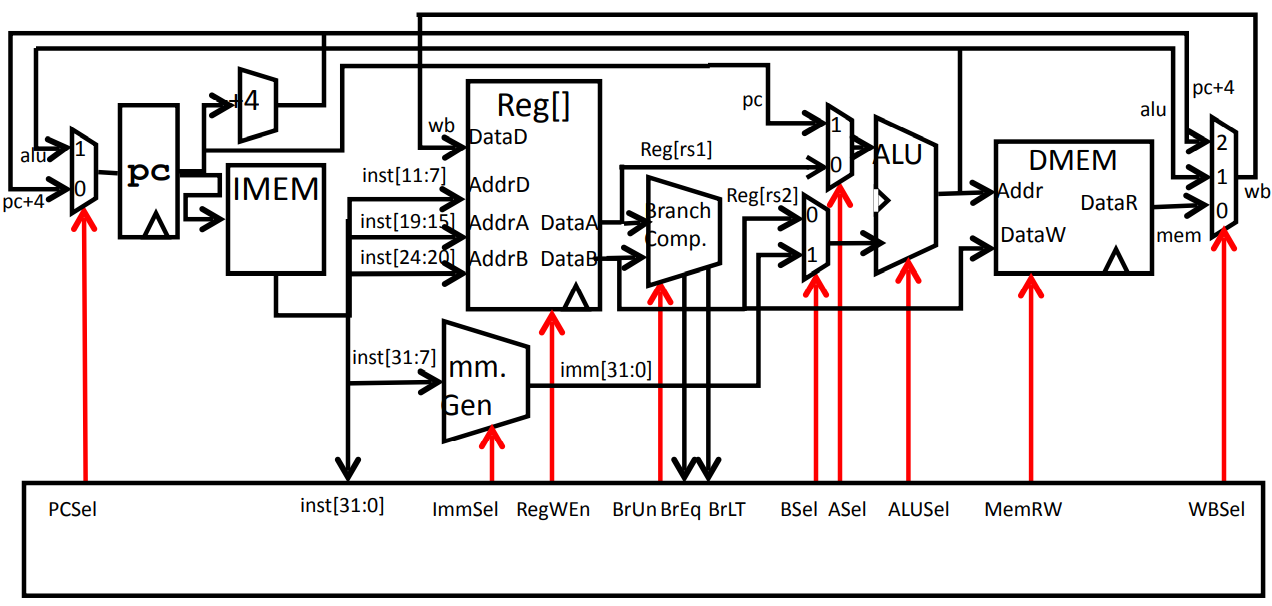
图1. RV32I单周期处理器数据通路
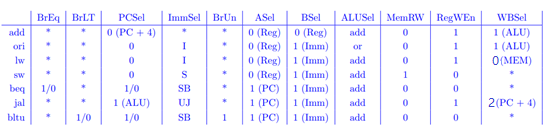
表1. 部分指令的控制信号
回答问题:参考上面的图表,分别写出slli指令和AUIPC指令的控制信号
参考信息如下:
SLLI用法举例: sllix11,x12,2 表示 x11 = x12«2(Shift Left Logical Immediate)
SLLI指令编码格式:

AUIPC指令用法举例:
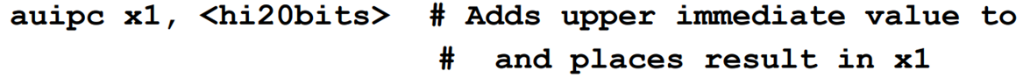
AUIPC指令编码格式:

更多关于RISC-V指令的信息可参考:
http://inst.eecs.berkeley.edu/~cs61c/resources/RISCV_Green_Sheet.pdf
ANS:
| name | BrEq | BrLT | PCsel | ImmSel | BrUn | ASel | BSel | ALUSel | MemRW | RegWEn | WBSel |
|---|---|---|---|---|---|---|---|---|---|---|---|
| slli | 0 | I | 0 | 1 | shift | 0 | 1 | 1 | |||
| auipc | 1 | U | 1 | 1 | add | 0 | 1 | 1 |
2.尝试添加RISC-V指令: ss rs1, rs2, imm
指令的功能为: Mem[ Reg[rs1] ] = Reg [rs2 ] + immediate (存储两数之和)
回答问题:为了支持这条指令,对图1中的RV32I单周期处理器,需要添加的新功能部件是什么?现有的哪些部件需要改造?需要新添加的数据通路是什么? 为控制单元新添加的控制信号有哪些?
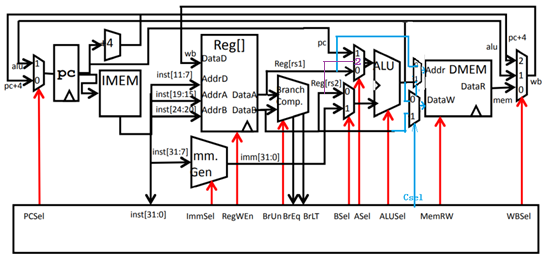
ANS:
|
|
- 单周期处理器的性能分析
时钟分析方法:
- 每个状态元件的输入信号必须在时上升沿之前稳定下来。
- 关键路径(critical path):电路中状态元件之间最长的延迟路径。
- tclk ≥ tclk-to-q + tCL + tsetup, 其中 tCL 是组合逻辑中的关键路径
- 如果我们把寄存器放在关键路径上,我们可以通过减少寄存器之间的逻辑量来缩短周期。
电路元件的延时如下所示:

关于硬件中的时钟的一些术语说明:
- 时钟(CLK):使系统同步的稳定方波
- 建立时间(setup time):在时钟边沿之前,输入必须稳定的时间
- 保持时间(hold time):在时钟边沿之后,输入必须稳定的时间
- “CLK-to-Q”延迟(“CLK-to-Q” delay):从时钟边沿开始,到输出改变需要多长时间
- 周期(period)= 最大延迟= “CLK-to-Q”延迟+CL延迟+建立时间
- 时钟频率=1/周期(即周期的倒数)
回答问题:
1.用到关键路径(critical path)的指令是哪一条?
提示:找到关键路径最长的那条指令,例如 add s1, t1, t2 指令的关键路径是:
IMEMread + RegFileRead + MUX +ALU + MUX , 哪条指令的关键路径更长? 找出来
ANS:
|
|
2.最小时钟周期 tclk是多少?最大时钟频率fclk是什么?假设tclk-to-q > 保持时间(hold time).
提示:tclk= PC寄存器的clktoQ + 关键路径(critical path)延迟 + RegFile_Setup
ANS:
|
|
4.流水线处理器设计(Pipelined CPU Design)
现在,我们将使用流水线方法来优化一个单周期处理器。流水线虽然增加了单个任务的延迟,但它可以减少时钟周期,提高吞吐量。 在流水线处理器中,多条指令重叠执行,体现了指令级并行性。
为了设计流水线,我们已经将单周期处理器分成五个阶段,在每两个阶段之间增加流水段寄存器。
接下来进行性能分析:
我们将使用与上一题相同的时钟参数:

回答问题:
\1) 这个五阶段流水线处理器的最小时钟周期长度和最大时钟频率分别是多少?
提示:
流水线处理器的最小时钟周期= max( clk-to-q + 某段的延迟 + 段寄存器setup_time)
ANS:
|
|
\2) 相比于单周期处理器,性能加速比(speed up)是多少?为什么加速比会小于5?
ANS:
|
|
1. 图2给出了RV32I五阶段流水化处理器示意图:
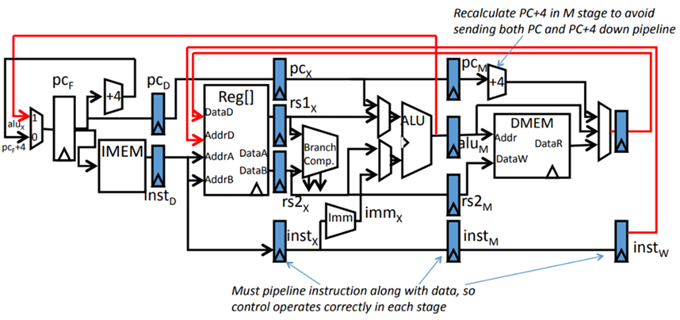
图2. RV32I五阶段流水处理器
在该处理器上执行以下指令序列:
|
|
注:寄存器堆先写后读,ID阶段的指令可以在同一个周期内得到WB阶段写回的数据;
回答问题:
(1) 假设硬件不检查和处理冒险,数据通路没有前向传递(Forwarding),在指令序列中插入空指令NOP,使得上述指令序列得到正确的执行结果。
|
|
(2) 假设对硬件不改变,是否可以编译优化:对代码的次序重排、寄存器换名,使得插入的空指令减少?
ANS:
|
|
(3) 假设进行硬件优化:数据通路中增加了前向传递(forwarding), 并增加了冒险检测单元。 哪些指令之间还是需要停顿?停顿几个周期?
|
|
6.在一个采用“取指、译码/取数(ID)、执行、访存、写回”的五段流水线中,以下指令序列中,在有数据转发(forwarding)、并将转移方向和转移地址计算提前到ID段进行(后面提供了文字和图片说明)的情况下,哪些指令执行时会发生流水线阻塞?各需要阻塞几个时钟周期?
|
|
对 “转移方向和转移地址计算提前到ID段” 提供一些补充信息供参考:
如果将跳转地址的计算放在ALU段,因此无论是beq这样的条件转移指令还是Jal这样的无条件转移指令,都要在ALU段才计算出转移地址,所以如下图3,当beq指令跳转时,要浪费两个周期(该指令的CPI=3)。同理,Jal指令也一样。
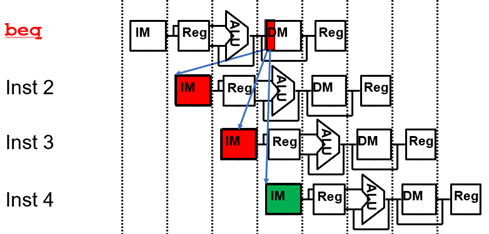
图3. 控制冒险导致的周期停顿
为了提高转移指令的性能,设计处理器时,可以将转移条件计算和转移地址计算都提前到流水线的ID段进行。如下图中红色圈出部分所示:
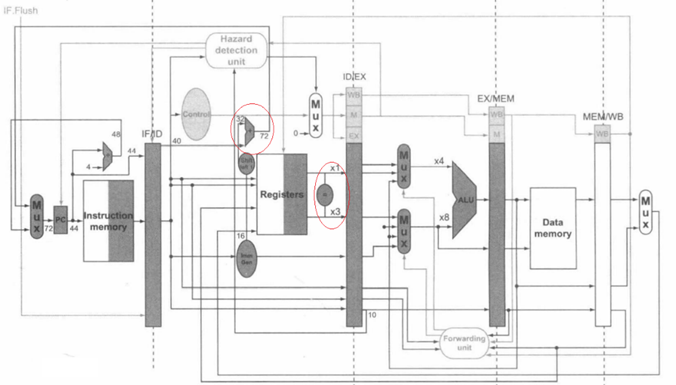
图4. 改进后的流水线数据通路(图片来源: 教材图4-60)
改进后,jal 和beq指令发生转移时,只需停顿一个时钟周期(CPI=2)。